
Data Pipelines
Data Pipelines
A data pipeline is a technique of shifting data from one place to the desired destination (for example, a warehouse). Along the way, data is optimized and transformed, reaching a point where it can be used and analyzed to develop and maintain business insights and to give a high level of data engineering services.
A data pipeline is mainly a set of steps involved in moving, organizing, and aggregating data. Manual steps are automated by modern data pipelines involved in optimizing and transforming continuous data loads. This means loading raw data into a staging table for interim and then adapting it before inserting it into the destination for Data Engineering Solutions.

Data Pipelines
A data pipeline is a technique of shifting data from one place to the desired destination (for example, a warehouse). Along the way, data is optimized and transformed, reaching a point where it can be used and analyzed to develop and maintain business insights and to give a high level of data engineering services.
A data pipeline is mainly a set of steps involved in moving, organizing, and aggregating data. Manual steps are automated by modern data pipelines involved in optimizing and transforming continuous data loads. This means loading raw data into a staging table for interim and then adapting it before inserting it into the destination for Data Engineering Solutions.
Advantages of a Data Pipeline
As the scope and breadth of the roles data plays increases, the problem also increases inimpact and scale. This is why data pipelines are considered critical, they are significant for real-time analytics to help you make faster, data-driven decisions for Data Pipeline Solutions or for a managed ETL service.
- Data storage in the cloud.
- Housing data in multiple different sources.
- Reliance on real-time data analysis.
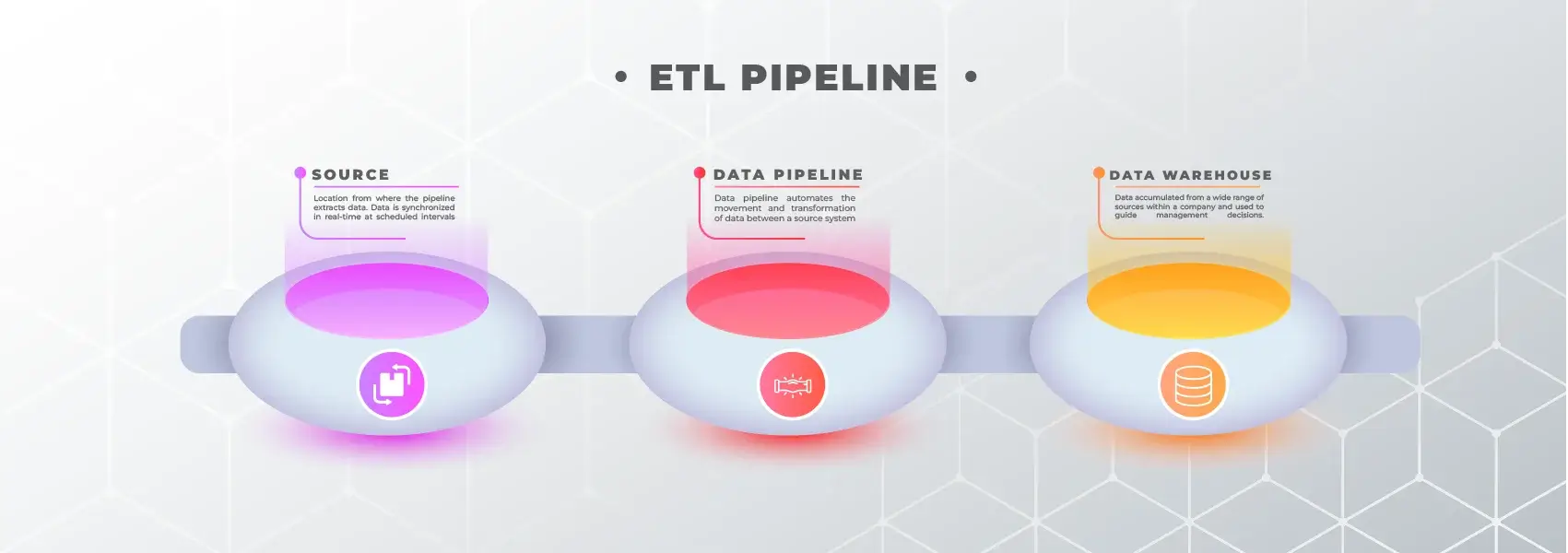
Elements of a Data Pipeline
All Data Pipeline Automation Services you will find claiming that data pipelines mainly consist of three elements:
1. Sources
Data comes from sources. Some of the commonest sources are relational database management systems such as CRMs like HubSpot and Salesforce, ERPs like Oracle and SAP, MySQL, IoT device sensors, and social media management tools.
2. Processing Steps
Data gets extracted from sources, changed and manipulated to business needs and thenmoved to its destination. This requires a series of processing steps and they are aggregation, grouping, filtering, augmentation, and transformation.
3. Destination
The destination is where the data arrives right in the very end, usually a data warehouse or datalake for analysis.
Furthermore, data pipelines can be continuous or batch and processing can directly happen within a system. Any data pipeline process needs to be conducted with thorough research and should be done in a careful manner, otherwise, data loss is a very glaring possibility, so yeah, do yourself a favor and follow these steps accordingly.