

AI and ML systems require a large volume of good quality data to ‘learn’. This is especially true for supervised learning techniques. The amount of data that is required varies depending on a few factors such as the algorithms or pattern of AI that is being utilized.
This leads many to believe that more is better. However, this is not the case. More data equates to more problems. This is because increased volumes of data require more preparation, labeling, management, and protection. Small projects end up becoming large tedious projects with huge amounts of data to process.
Once a business problem is identified, it is essential to determine which data is required and how much of it is needed. It is crucial to ensure that the amount of data is just right; not too much or too little. It is a common mistake to dive straight into the AI project without developing an understanding of the data that is required. So you may ask, what information about the data is required prior to commencing an AI project? There are a few key factors to take into account:
- Where is the data?
- What data do I already have?
- Do I require external or internal data?
- How do I overcome data access challenges?
- What features of this data are most important to me?
Obtaining an answer to these questions prevents users from drowning in large volumes of data and prevents more problems from being generated due to the sheer volume of information.
Understand your data better
In order to acquire the right amount of data for your AI services project , you need to develop a better understanding of the data itself. You need to know where and how the data will fit into your AI services project. A useful visual demonstration of this concept is seen in the DIKW pyramid ( please refer to figure 1)
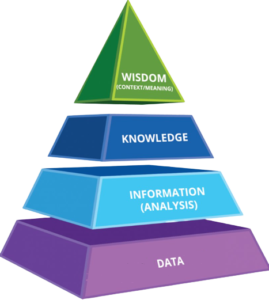
Based on the DIKW pyramid, we can deduce that a good foundation of data enables better insight into the next level : information. Having a good understanding of information allows you to answer questions about the data and appreciate how the different pieces fit together to form the perfect puzzle. As you continue to build on the pyramid, the knowledge layer enables organizations to understand the underlying patterns. The most value from the information and data is obtained from the top level of the pyramid: Wisdom. Wisdom provides organizations with insights regarding the cause and effects of decision making.
AI focuses mainly on the knowledge layer in the DIKW hierarchy as machine learning is able to identify patterns in the information layer. Although machine learning is able to identify patterns , it reaches its limitations when it comes to reasoning. This is where human input is required to rationalize why patterns are occurring in a particular manner. Users will be able to identify this limitation when using chatbots. Machine based NLP is able to understand speech but reaches its limitations when it comes to rationalization. For an instance, if a voice assistant is asked about the weather , it will be able to provide an answer to this question. However if it is asked whether a user should take an umbrella when going out or not, it will not be able to comprehend that the user is trying to ask about the weather. This is where human input is required to provide insight to the voice assistant.
How to avoid failure
Big data has taught us how to process, manipulate and analyze large volumes of data. This knowledge has been supplemented by machine learning as it is able to manage a wide variety of unstructured and structured data.
Although this has made it possible for us to manipulate large quantities and various types of data, big data has also posed some challenges for organizations. It is not uncommon for organizations to focus on the functional aspects of AI rather than opt for a data-centric approach. By focusing on the functional aspects, many organizations fail with AI services projects.
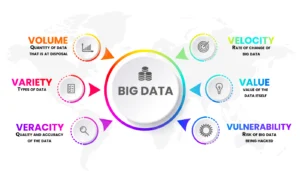
In order for a project to be handled well and for deadly mistakes to be avoided, it is essential not only to gain a better understanding of both AI and machine learning but also to comprehend some important features of big data. The features of big data can be classed as the essential V’s :
A few examples of these features of big data are as follows:
- Volume: Quantity of data that is at disposal
- Variety: Types of data ( unstructured, semi-structured or structured)
- Veracity: Quality and accuracy of the data
- Velocity: Rate of change of big data
- Value: value of the data itself
- Vulnerability: Risk of big data being hacked
A tip for success with AI services projects is to be able to manage big data projects. Organizations that are able to implement AI successfully have one thing in common: their ability to manipulate and manage big data. Those that are unsuccessful with their AI services projects tend to have an incorrect approach to the project and are primarily focused on application development.
What kills AI projects?
Lack of necessary data and lack of understanding of the data tends to kill AI services projects. Organizations that tend to proceed with their AI services projects without having a good understanding of these fundamentals tend to face failure very shortly after the initiation phase of the project. Here are a few tips to ensure that you don’t fall into this trap:
- Ensure that you have the necessary and adequate amount of data
- Develop an understanding of the data
- Use the CRISP-Dm methodology
- Have a data centered approach
Bottom Line:
In summary, it is essential for businesses to develop a good understanding of their data requirements prior to commencing an AI project. This will ensure that the project launches successfully with just the right quantity and type of data. The DIKW pyramid is a useful tool to enhance understanding of data.
If you enjoyed reading this blog post , keep following FuturisTech for more.